Matplotlib 系列:手动设置时间序列折线图的刻度
前言
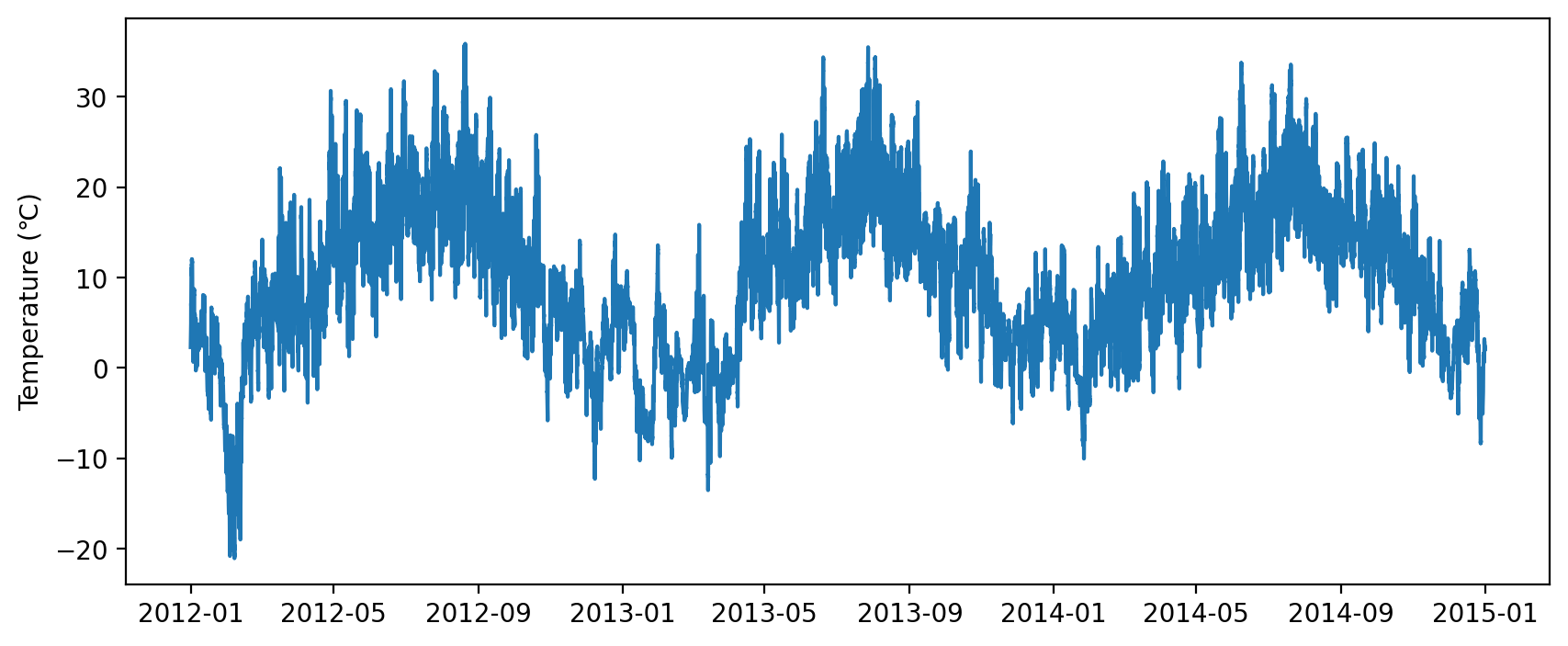
Matplotlib 中画折线图用 ax.plot(x, y),当横坐标 x 是时间数组时,例如 datetime 或 np.datetime64 构成的列表,x 和 y 的组合即一条时间序列。Matplotlib 能直接画出时间序列,并自动设置刻度。下面以一条长三年的气温时间序列为例:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv('test.csv', index_col=0, parse_dates=True)
series = df.loc['2012':'2014', 'T']
fig, ax = plt.subplots(figsize=(10, 4))
ax.plot(series.index, series)
ax.set_ylabel('Temperature (℃)')
print(ax.xaxis.get_major_locator())
print(ax.xaxis.get_major_formatter())
<matplotlib.dates.AutoDateLocator object at 0x000001AC6BF89A00>
<matplotlib.dates.AutoDateFormatter object at 0x000001AC6BF89B20>