Python 相关资源汇总(持续更新中)
简单汇总罗列一下我在网上找到的还不错的 Python 相关资源,包括语言本身以及各种常用库的教程,当然触手可及的官方文档就不收纳了。通通都是免费资源(付费的咱也看不到),分享给有需要的读者。不过互联网资源并非恒久不灭,说不定哪天域名就失效了,或是原作者突然隐藏文章,且看且珍惜吧。
简单汇总罗列一下我在网上找到的还不错的 Python 相关资源,包括语言本身以及各种常用库的教程,当然触手可及的官方文档就不收纳了。通通都是免费资源(付费的咱也看不到),分享给有需要的读者。不过互联网资源并非恒久不灭,说不定哪天域名就失效了,或是原作者突然隐藏文章,且看且珍惜吧。
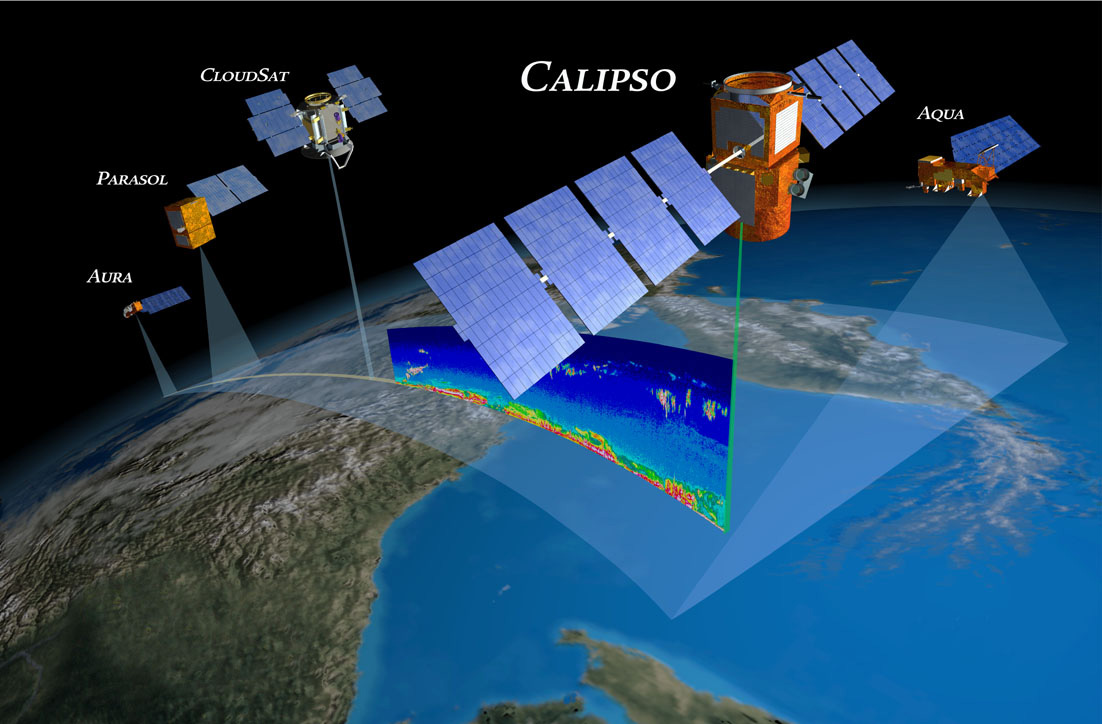
CALIPSO 卫星的 L2 VFM(Vertical Feature Mask)产品根据激光的后向散射和消光信息,将激光通过的各高度层分类为云或气溶胶。该产品在现实中的表现如下图所示:卫星一边在轨道上移动一边向地面发射激光脉冲,相当于在地面上缓缓拉开一幅“画卷”,VFM 描述了“画卷”上云和气溶胶的分布和分类情况。
处理 VFM 产品的难点在于:
(N, 5515) 的形状,N 表示卫星移动时产生了 N 次观测,但 5515 并非表示有 5515 层高度,而是三种水平和垂直分辨率都不同的数据摊平成了长 5515 的数组。因此处理数据时需要参照文档的说明对 5515 进行变形。网上能找到的代码有:
笔者也曾写过两次教程:
本文是对旧教程的翻新,会对 VFM 数据的结构进行更多解释,对代码也进行了更新。本文使用 pyhdf 读取 HDF4 文件,用 Matplotlib 3.6.2 画图。为了方便画图,用了一些自制的函数(frykit)。虽然基于 Python,但希望能给使用其它语言的读者提供一点思路。
完整代码已放入仓库 calipso-vfm-visualization。
这回来介绍一下如何利用管道(pipe)风格将 Pandas 相关的代码写得更易读,不过首先让我们看看隔壁 R 语言中管道是怎么用的。假设输入是 x,经过连续四个函数的处理后得到输出 y,代码可以按顺序写:
x1 <- func1(x, arg1)
x2 <- func2(x1, arg2)
x3 <- func3(x2, arg3)
y <- func4(x3, arg4)
相信大伙对 NumPy 和 SciPy 里的插值比较熟:已知坐标值 xp 和变量值 fp,调用函数计算变量在目标坐标 x 上的数值。例如 np.interp 的 API 就是
np.interp(x, xp, fp)
Pandas 的 Series 和 DataFrame 对象也有插值方法 interpolate,默认做线性插值。但其功能与 NumPy 和 SciPy 不太一样。以一个序列对象 s 为例:
# 缺测部分和有效部分.
invalid = s.isna()
valid = ~invalid
# 对应于xp.
s.index[valid]
# 对应于fp.
s.values[valid]
# 对应于x.
s.index
# 两式大致等价.
s.interpolate(method='index').values
np.interp(s.index, s.index[valid], s.values[valid])
即 Pandas 的插值是要利用序列的有效值当 xp 和 fp,去填补缺测的部分。所以调用 s.interpolate 时我们不需要传入形如 x 的参数,而是应该在调用前就通过 s.reindex 之类的方法将 x 融合到 s 的索引中。这么说可能有点抽象,下面就以图像直观展示 Pandas 里插值的效果。本文不会涉及到具体的插值算法(最邻近、三次样条……),仅以线性插值为例。
Python 的取模运算 r = m % n 相当于
# 或q = math.floor(m / n)
q = m // n
r = m - q * n
即取模的结果是被除数减去地板除的商和除数的乘积,这一规则对正数、负数乃至浮点数皆适用。
当 n 为正数时。显然任意实数 x 可以表示为 x = r + k * n,其中 0 <= r < n,k 是某个整数。那么有
x // n = floor(r/n + k) = k
x % n = x - x // n = r
即 x % n 的结果总是一个大小在 [0, n) 之间的实数 r。当 n = 10 时,以 x = 12 和 x = -12 为例:
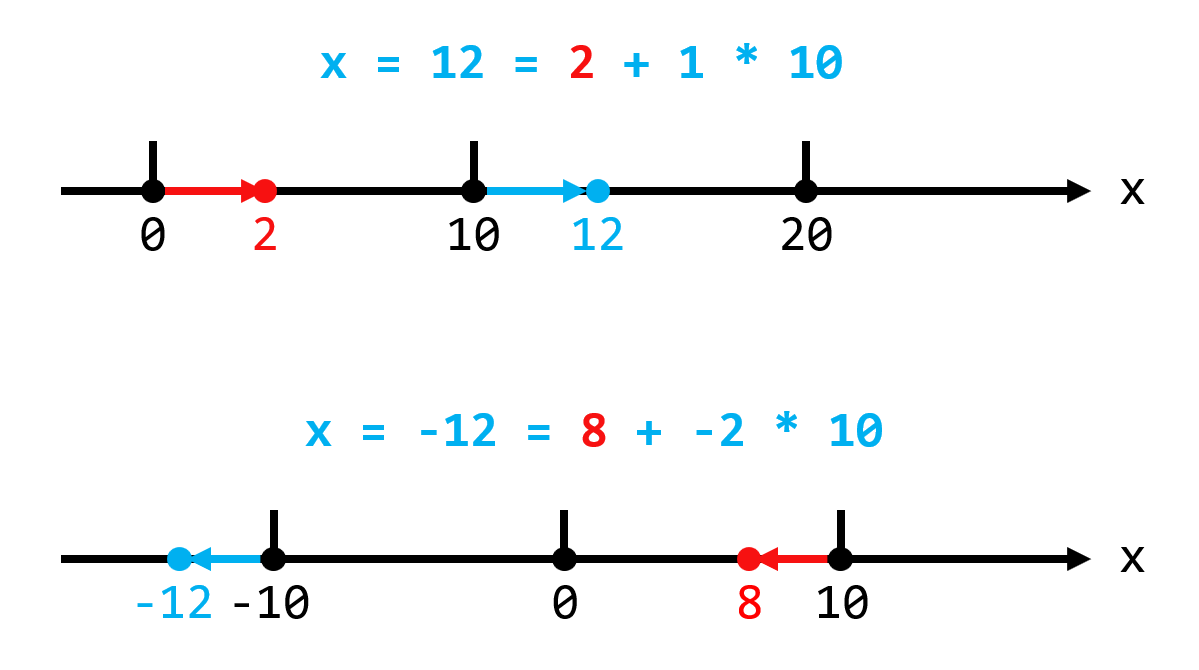
如果以 n 为一个周期,那么 x = 12 就相当于往右一个周期再走 2 格,x % n 会消去这个周期,剩下不满一个周期的 2;x = -12 相当于往左两个周期后再往右走 8 格,x % n 会消去这两个周期,剩下不满一个周期且为正数的 8。
再本质点说,取模运算就是在 [0, 10) 的窗口内进行“衔尾蛇”移动:
12 向右超出窗口两格, 12 % 10 = 2,即右边出两格那就左边进两格。-12 向左超出窗口 12 格,-12 % n = 8,即左边出 12 格那就右边进 12 格,发现还是超出左边两格,再从右边进两格,最后距离零点 8 格。说到测量程序的运行时间这件事,我最早的做法是在桌上摆个手机,打开秒表应用,右手在命令行里敲回车的同时左手启动秒表,看屏幕上程序跑完后再马上按停秒表,最后在纸上记下时间。后来我在 Linux 上学会了在命令开头添加一个 time,终于摆脱了手动计时的原始操作。这次就想总结一下迄今为止我用过的那些测量时间的工具/代码。
今天改程序时脑海里突然蹦出这个问题,更宽泛地说,是修饰词或者偏正结构的先后顺序,例如
upper_ax 和 bottom_ax,ax_upper 和 ax_bottom。start_date 和 end_date,date_start 和 date_end。一旦开始疑惑,焦虑便随之而来:哪一种比较好呢?我之前的代码里好像两种写法都出现过,有没有什么现成的规范可以参考呢?越想越不痛快,所以赶紧上网找点前人经验来背书。意外的是,网上大部分文章都在讨论如何取有意义的变量名,而关于这个问题的寥寥无几,也许是因为太细节、太“语法”了?现归纳两篇我看过的帖子以供参考。
首先在 stack overflow 上找到了一模一样的提问:是用 left_button 和 right_button,还是 button_left 和 button_right 更好呢?提问者自己觉得前者符合英文语序,读起来更加自然,而后者强调了变量的重点在于按钮,而左和右是额外的补充信息。有评论指出后者在 IDE 里更方便,因为你一键入 button,就会自动联想出所有带后缀的版本。这也挺符合人的联想过程,我们肯定是先想到“我要找按钮”,再明确具体要什么样的按钮。当然也有评论给出了经典的废话:与其纠结哪一种约定,任选一种并在项目里维持一致性最重要!好家伙,要是我如此豁达还会来搜这种鸡毛蒜皮的问题吗?
本文研究一个小问题:如何将长度为 N 的列表等分为 n 份?该问题的示意图如下
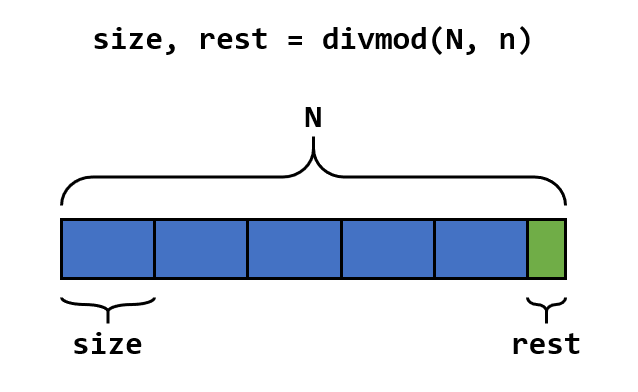
N 除以 n 的商为 size,余数为 rest,数值满足 0 <= rest < n or size(除法规则请见 Python 系列:除法运算符)。当 N 是 n 的倍数时,rest = 0 ,列表正好被等分为 n 份,每份含 size 个元素;而当 N 不是 n 的倍数时,rest > 0,按前面的分法会剩下 rest 个元素。对于后一种情况来说并不存在真正的等分,只能说希望尽量等分,问题的重点也落在了如何处理这 rest 个元素上。
笔者初次使用 MODIS 二级气溶胶产品时,一下就被密密麻麻一堆变量搞懵了:很多变量名字里带个 Optical_Depth,这我能猜到,就是气溶胶光学厚度,但各种 Corrected、Effective、Best、Average、Small、Large 的前后缀鬼知道是什么。看过的论文基本不说具体用的哪个变量,各种教程也不会告诉你这些亲戚间的差异,似乎这件事一点也不重要。本着 know your data 的心态,我在翻阅了 MODIS 的几个官网后总算从反演的原理中稍微体会到了这些前后缀的意义。现将学习经验总结归纳如下,希望能帮到和我一样疑惑的小伙伴。同时本文还会提供简单的 Python 示例代码。
如果嫌正文太啰嗦,可以直接跳到文末的总结部分,那里直接给出了各个变量的使用建议。
之前我在 Cartopy 系列:从入门到放弃 一文中定义了这样一个函数
def set_map_extent_and_ticks(
ax, extent, xticks, yticks, nx=0, ny=0,
xformatter=LongitudeFormatter(),
yformatter=LatitudeFormatter()
):
...