相信大伙对 NumPy 和 SciPy 里的插值比较熟:已知坐标值 xp 和变量值 fp,调用函数计算变量在目标坐标 x 上的数值。例如 np.interp 的 API 就是
np.interp(x, xp, fp)
Pandas 的 Series 和 DataFrame 对象也有插值方法 interpolate,默认做线性插值。但其功能与 NumPy 和 SciPy 不太一样。以一个序列对象 s 为例:
# 缺测部分和有效部分.
invalid = s.isna()
valid = ~invalid
# 对应于xp.
s.index[valid]
# 对应于fp.
s.values[valid]
# 对应于x.
s.index
# 两式大致等价.
s.interpolate(method='index').values
np.interp(s.index, s.index[valid], s.values[valid])
即 Pandas 的插值是要利用序列的有效值当 xp 和 fp,去填补缺测的部分。所以调用 s.interpolate 时我们不需要传入形如 x 的参数,而是应该在调用前就通过 s.reindex 之类的方法将 x 融合到 s 的索引中。这么说可能有点抽象,下面就以图像直观展示 Pandas 里插值的效果。本文不会涉及到具体的插值算法(最邻近、三次样条……),仅以线性插值为例。
以数值为索引的序列
import numpy as np
import pandas as pd
index = pd.Index([1, 4], name='x')
s = pd.Series(10 * index, index=index, name='y')
target = np.arange(6)
作为例子的序列 s 只有两个值:10 和 40,对应的坐标是 1 和 4。现希望插值得到坐标 0 - 5 上的值,所以通过 reindex 方法将目标坐标融合到 s 的索引中,再调用 interpolate。过程如下图所示:
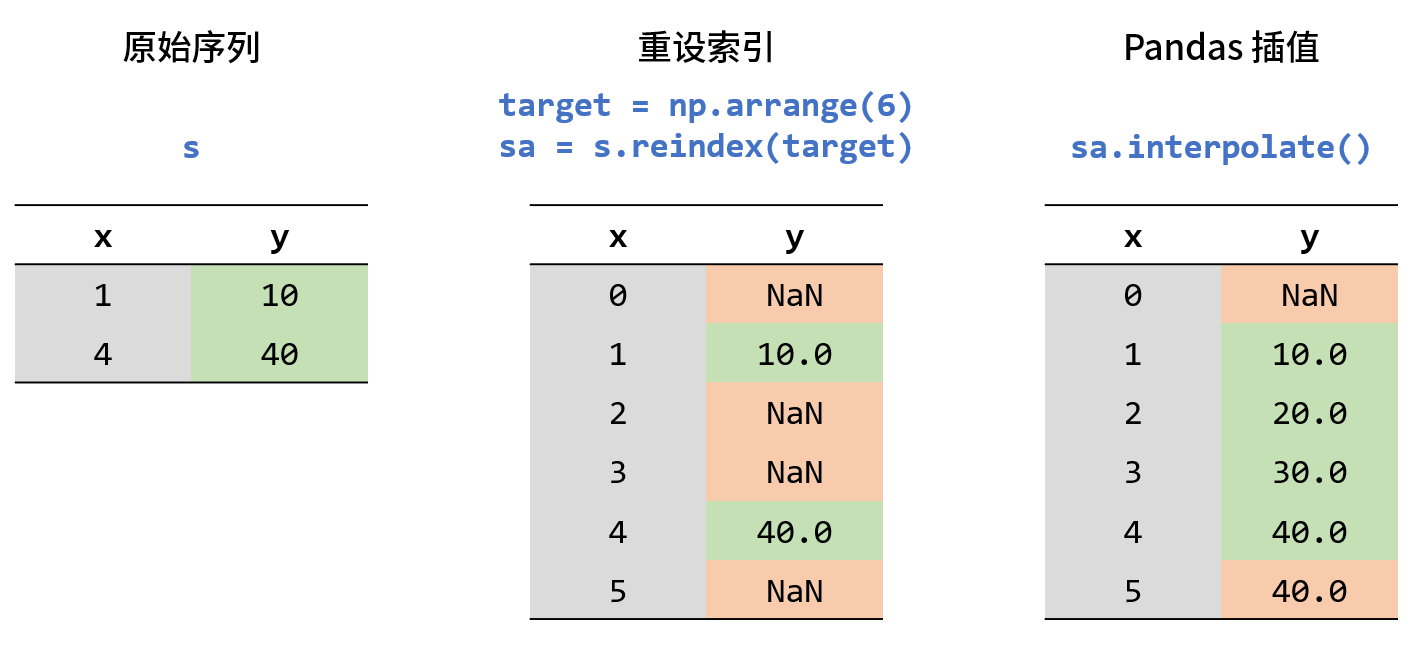
图中绿色部分代表原始值和线性插值的结果,红色部分代表缺测或特殊的插值结果。可以看到 s.reindex 向序列中引入了浮点型的 NaN,所以 sa 的数据类型由整型偷偷转换成了浮点型。坐标 2 和 3 处的值由线性插值得到 20.0 和 30.0,这符合我们的预期;坐标 0 和 5 在 s 的坐标范围之外(即要做外插),sa.interpolate 的默认行为是保留序列开头的 NaN,用最后一个有效值去填充结尾处的 NaN,所以最后坐标 0 对应 NaN,5 对应 40.0。
这个例子中目标坐标是等间距的,那如果不等间距会怎样?结果如下图所示:
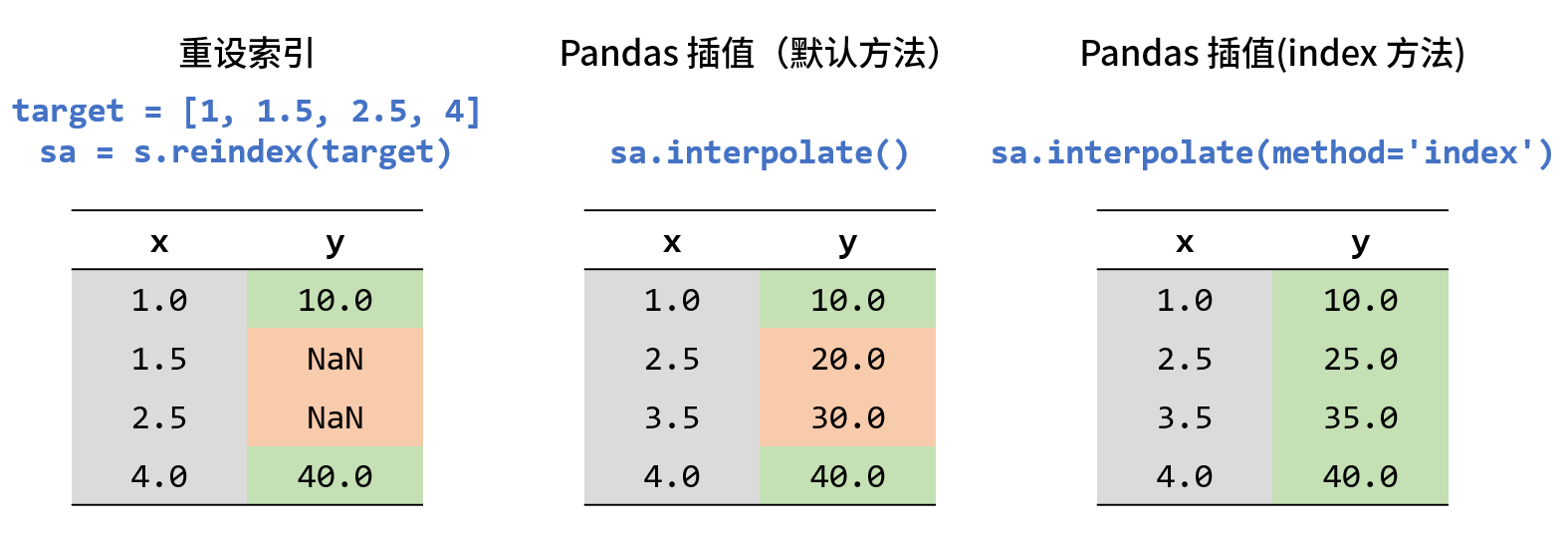
可以看到 sa.interpolate() 在 2.5 和 3.5 位置的结果是错误的。原因是 interpolate 有个指定插值方法的参数 method,默认值为 'linear',会无视索引 x 的具体数值,认为 y 是等距排列的,进而插出错误的结果。如果你预先知道序列的每一行是等距排列的,那么可以放心调用无参数的 interpolate(),否则就需要指定 method 为 'index' 或 'values',以 x 的数值作为目标坐标来做线性插值,得出 2.5 对应 25.0,3.5 得出 35.0。另外当 method 取 quadratic、cubic、spline 等高级方法时,自然会用上索引的数值。
再考虑一种特殊的情况:目标坐标中不含 s 的坐标值,而是恰好穿插在其中。那么根据 reindex 的效果,s 原来的标签会被全部丢弃掉,得到一个全部缺测的序列 sa,于是 sa.interpolate 将不会有任何意义。笔者想到了三种办法来解决这一问题,其一便是用 NumPy 或 SciPy 正儿八经做插值计算,再老老实实地用得到的数组构造新序列,如下图所示:

可以看到 sa.interpolate() 完全无效,而引入 NumPy 的线性插值后能得到预期结果。np.interp 的默认行为是用序列首尾的有效值填充外插的部分,所以图中有两处红色。
方法二是用 xarray 代替 Pandas 做插值。虽然 xarray 是 Pandas 的亲戚,但 xarray 的插值方法 interp 反而与 NumPy 和 SciPy 接近,调用时需要给出目标坐标值。结果如下图所示:

该方法中需要用 sa.to_xarray 将序列转为 DataArray,插值完后再用 to_series 变回序列。DataArray.interp 底层使用的是 scipy.interpolate.interp1d 函数,默认不会做外插,所以最后结果的首尾保留了 NaN。
第三种方法只用 Pandas 自己的功能实现,但逻辑稍微麻烦些:s.index 与目标坐标求并集(会自动排序),然后进行 reindex,再调用 interpolate,最后从结果中索引出目标坐标的行。效果下图所示:

结果嘛没什么可说的,开头保留了缺测,结尾的缺测直接前向填充。需要注意的地方是,这里 interpolate 不能取 method='linear',否则会插出错误的数值。
以时间为索引的序列
时间序列的插值基本同上一节的描述。一个小区别是,method 中 index 和 values 多了一个别名 time,效果是一样的。这节真正要讲的是 asfreq 和 resample 的插值。
粗略来说,asfreq 的效果是以序列的起止时间为范围,生成一串等间距的时间戳(例如逐日、每小时、每分钟……),再以该时间戳做 reindex。所以将 asfreq 和 interpolate 方法串起来,可以轻松实现等间隔时刻的内插,如下图所示:

图中通过 s.asfreq('D').interpolate() 便能实现逐日的线性插值。与之相对照的笨方法是:
target = pd.date_range(s.index[0], s.index[-1], freq='D')
s.reindex(target).interpolate()
在时间序列重采样相关的教程中可能会出现 s.resample('D').interpolate() 的用法。查看源代码会发现等价于 s.asfreq('D').interpolate(),依旧可以归纳为上图。
结语
总结一下前面的结论:
- Pandas 中的
interpolate的作用是通过插值填充缺测部分。 - 默认做无视索引数值的线性插值,可以通过
method参数修改这一行为。 - 插值前需要用
reindex之类的方法引入目标坐标。 - 可以用 xarray、NumPy 或 SciPy 做好插值后再导回 Pandas。
- 时间序列可以用
asfreq或resample处理后再进行插值。
本文简单图解了 Pandas 插值的基本行为和使用场景,但考虑到 interpolate 方法的参数较为复杂,仍然可能有错漏的地方,还请读者批评指正。