这是物理海洋学家 Ken Hughes 在 2021 年发表的博客文章,原文标题为 A better way to code up scientific figures。以 Matplotlib 和 Matlab 为例,强调了模块化思想对于科研作图代码的帮助。我很少看到关于作图方法论的文章,所以翻译出来交流学习。
我画一张出版级别的科研配图一般需要写 100 - 200 行代码,这个长度有点点危险,因为很容易写出能正常运行但又一团糟的东西。如果代码片段都很短还可以从头重写,但如果代码有上千行,提前做好规划会更明智一些。不过在这两种极端情况之间潜藏着另一种吸引人的做法:写出一段当时感觉无比连贯,但以后会让你吃苦头的脚本。
假设你想画一张中等复杂度的图片,类似下面这张:
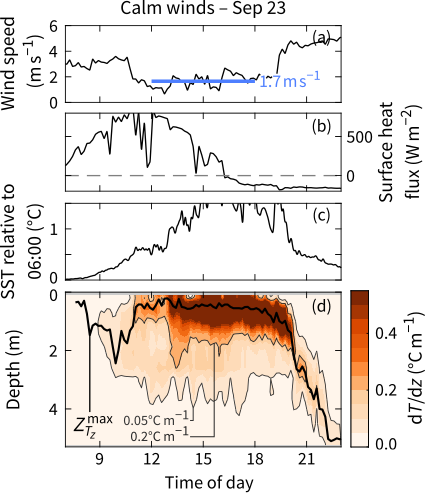
相应的脚本可以被设想为一系列步骤:
- 从 csv 文件中读取数据
- 去掉被标记(flagged)的数据
- 创建四张子图(subplot)
- 第一行里画数据随时间的变化
- 给 y 轴添加标签(label)
- 设置 y 轴的范围
- 第二行和第三行重复步骤 4 - 6
- 添加填色图(contour)和灰色的等高线
- 给时间轴添加标签
- 添加各种标注(annotation)
如果你对 Python、Matlab 或 R 之类的语言很熟,就能轻松地将步骤 1 - 10 扩充为一股“意识流”。像什么添加子图、给多个面板(panel)加标签、设置坐标轴范围等操作都可以不假思索地写出,因此你的脚本常常在不知不觉间超过 100 行。
一般来说,笔记本电脑的屏幕或者外接显示器最多显示 40 - 50 行代码,所以你没法一眼看出脚本里的所有步骤。相反,你得靠你的短期记忆。
不过先等一下!假设你想快速测试几个改动,于是你临时注释掉了几行代码,临时重写了一些变量,或者临时新添了一个面板图。
恐怕你已经有种不详的预感了吧?这些临时改动中有一些会被保留,剩下的会改回去。最后原本简单的步骤 1 -10 变成了 1,1b,2,2b,3,3b,6,5,4,7,8,9,10,10b,10c,11,12。
当你几个月后必须重温这个混乱的脚本时(例如第二审稿人给了点修改意见),其毛病才会真正显露出来。你写这个脚本的时候是靠短期记忆来理解所有片段是如何组合在一起的,但几个月后你肯定会忘个精光。
作为一名科学家,过去几年里我写了太多这种混乱的作图脚本。即便到了现在,有时为了快速出结果我还是会这么写。不过在大部分时间里,我都会采用一种更好的编写方法。
编写作图脚本的模块化方法
Ten simple rules for quick and dirty scientific programming 中的第四条就是模块化你的代码,并且这也正是本文将要给出的建议。
我写的每个作图脚本都由十几个函数组成,有读取数据的函数、画多个面板的函数、每张折线图对应的函数、给所有 axes 加标签的函数等。下面是一个极简的 Python 例子,在我屏幕上的效果是这样的:
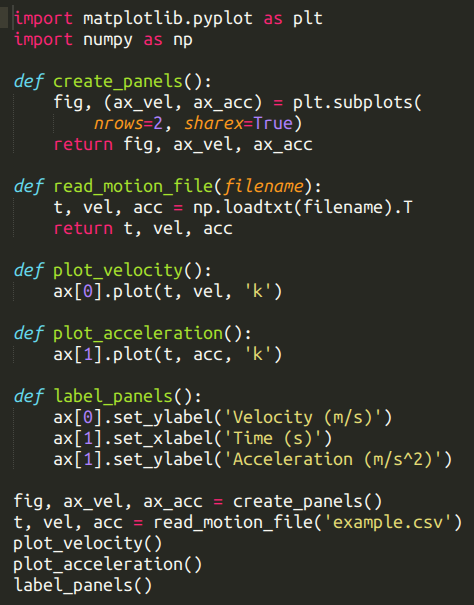
你可能会觉得定义一堆单行函数有点小题大做,还会把脚本的长度变成原来的两倍。但请你相信我,只要你的脚本比这个小例子更复杂,模块化方法就能使你受益。
具体来说,将多行代码归为函数有以下四个好处:
1. 强迫你为脚本列出大纲
我在前面提过,很容易将一个作图脚本设想为一系列步骤,但据我的经验来看,科学家们很少会把这些步骤记录下来。不过如果你创建了一系列函数,就要求你先有一个高层级的概览(overview)。在这个例子里,最后五行代码自然构成了大纲。
2. 你可以用大白话描述你的代码
你不会 Python 也能看懂例子脚本中的步骤,函数都是用大白话取的名,你只用看函数名就行。你当然可以用注释达成类似的效果,但在编写过程中注释内容往往会和代码的实际作用脱节。
3. 定位到具体的命令更简单
假设你想改变一张面板图里几条线的颜色,如果你的作图脚本有几百行,就得花点时间定位到需要改动的地方。但当几百行代码被细分到少量的函数里时,定位就会快很多。这跟用目录来查教科书的某一面是一个道理。
4. 你可以只注释一行而不是一整块代码
在迭代到成品图的过程中,你可能会测试不同的排列、数值或图形种类。通过注释和反注释代码块来实现当然是可以的,但这种做法不仅麻烦,而且可以说是一个 坏习惯。相反,如果你写的每个函数都只完成特定的任务,你就只用注释或反注释一行代码来进行调整。比方说我要修改上面的例子,操作大概如下图所示:
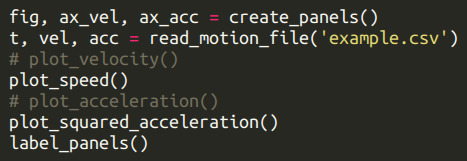
你的函数不必完美
在我最初的示例中只有一个函数带参数,这无疑是种糟糕的写法,按理来说每个函数都应该有参数或能接受变量。对此我倒是不怎么担心,因为我知道当 Python 在函数体或输入里找不到所需的变量时就会到函数外面去找。由于每个函数都只用一次,所以不显式传递变量也没问题。(你可能会疑惑创建一次性的函数有没有价值,我的回答是 肯定的。)
在写 Matlab 时我也采取了几乎一样的方针,唯一的差别是需要额外将整个脚本用一个父函数封装,不然没法定义嵌套函数。我的脚本大致长这样:
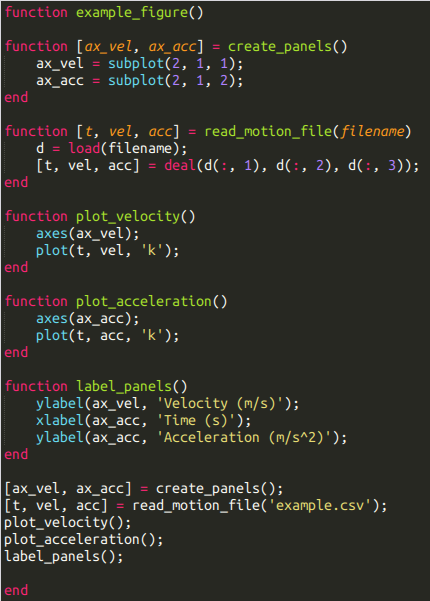
“多用函数”的建议并不新鲜
科学领域常用的编程语言(Python、Matlab、R、Julia)非常适合交互式使用。在命令行窗口输入 284*396 就会输出 112464。但命令行也就止步于此了,你很快意识到你想连续执行多行命令。因此你把这组连续的命令移到了一个脚本里,然后点击运行按钮。与命令行窗口不同的是,这种脚本能带你走得更远。(当我提到脚本时,我也在暗指那些能计算的 notebook。类似脚本,notebook 同样混乱,而且会助长糟糕的编程习惯。)
许多科学家能在不懂函数的情况下完成任务,而一个不会用函数的程序员则压根找不着工作。这种不一致性使我不确定本文的定位是否合适。一方面来说,多用函数的建议听起来像废话,就好比我建议科学家写论文的时候记得带标题一样。另一方面,我看过了太多擅长计算机的科学家写出来的混乱不堪的作图脚本,所以坚信“多用函数”是一条既有价值又深刻的建议。
我并不是唯一一个试图弥合程序员和科学家之间鸿沟的人。正如软件可持续性研究所的 Simon Hettrick 所说:“这对写代码的科学家意味着什么?只有当他们当了软件工程师才算真正的程序员吗?我觉得不是。我认为科学家们应该把计算机编程作为一种探索性的工具来推动他们领域里的发现,这跟他们使用其它方法和工具并没有什么两样。但是作为科学家的程序员也能通过学习模块化、抽象化和数据结构而受益。”