Numpy 系列:统计序列里零值连续出现的次数
需求
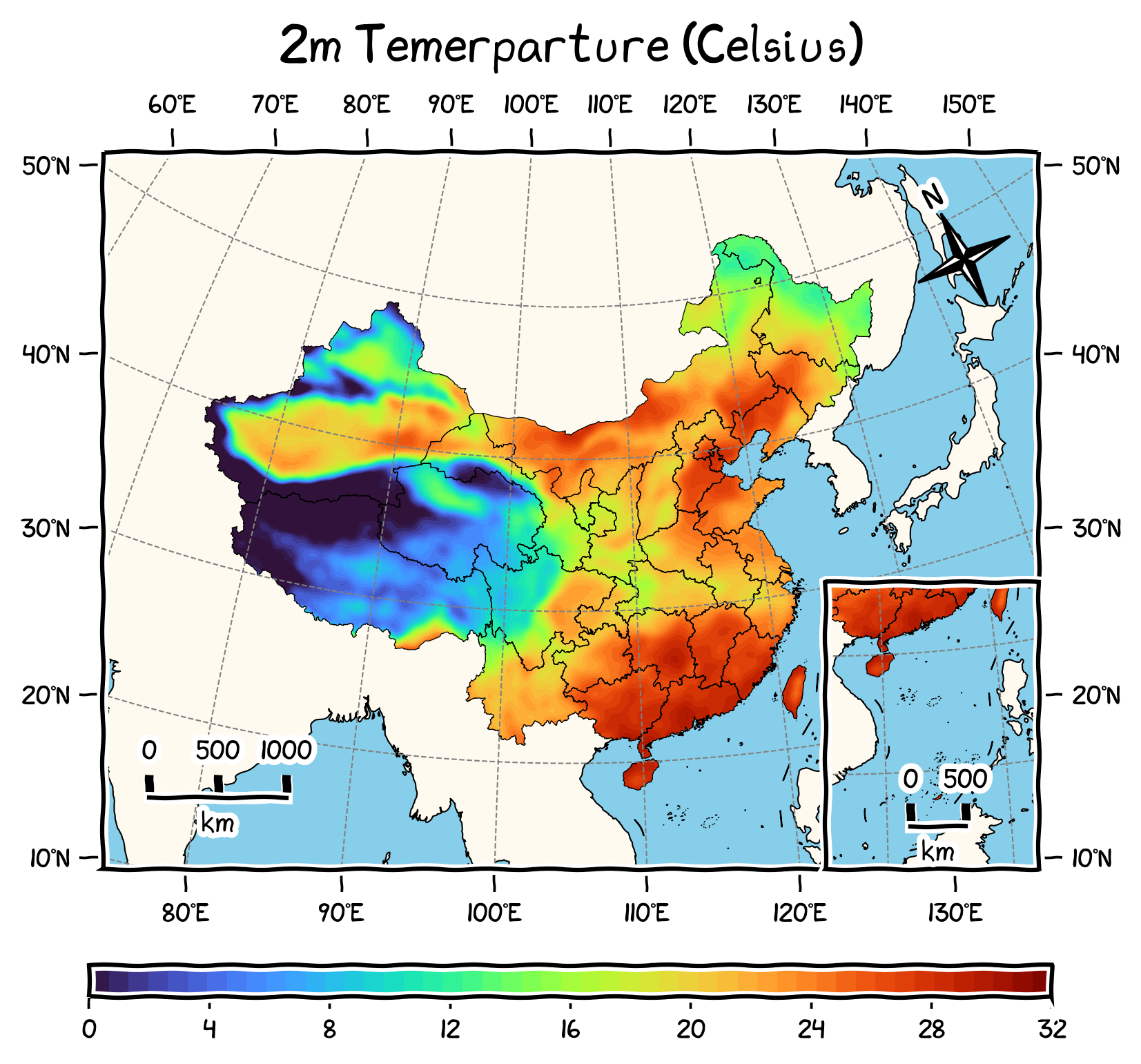
以前处理功率时间序列时经常遇到一大段时间里功率值虽然没有缺失,但全是零的异常情况,为了找出这些连续为零的时段,当时设计了一个统计序列里零值连续出现次数的函数,效果如下图所示:
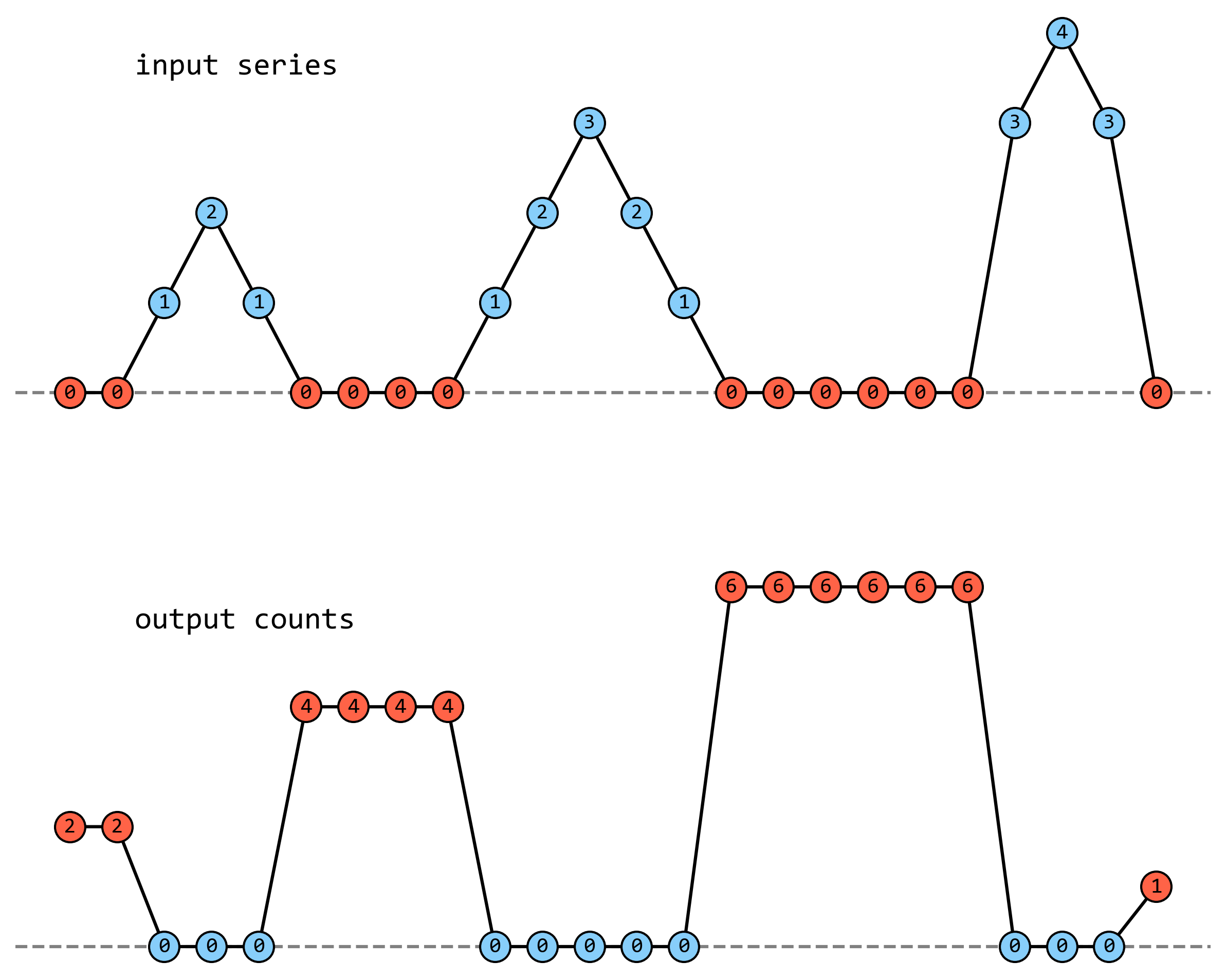
输入序列是
series = np.array([0, 0, 1, 2, 1, 0, 0, 0, 0, 1, 2, 3, 2, 1, 0, 0, 0, 0, 0, 0, 3, 4, 3, 0])
其中有四段零值,长度依次为 2、4、6、1。输出序列与输入序列等长,输入序列中非零位置的数值为零,零值位置数值为零值连续出现的次数。