本文研究一个小问题:如何将长度为 N 的列表等分为 n 份?该问题的示意图如下
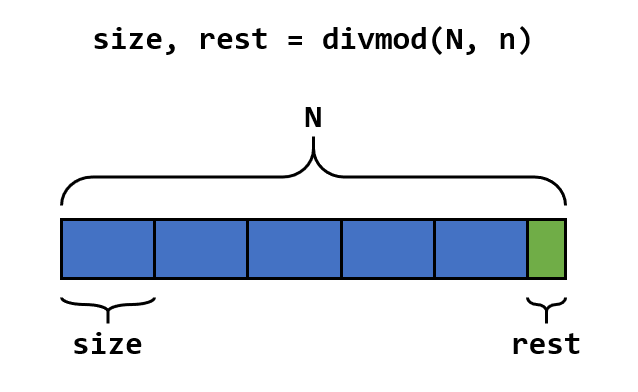
N 除以 n 的商为 size,余数为 rest,数值满足 0 <= rest < n or size(除法规则请见 Python 系列:除法运算符)。当 N 是 n 的倍数时,rest = 0 ,列表正好被等分为 n 份,每份含 size 个元素;而当 N 不是 n 的倍数时,rest > 0,按前面的分法会剩下 rest 个元素。对于后一种情况来说并不存在真正的等分,只能说希望尽量等分,问题的重点也落在了如何处理这 rest 个元素上。
策略一是,若余数不为零,那么 size 顺势增大一位,这样一来肯定能涵盖剩下的元素。
def split_list_1(lst, n):
size, rest = divmod(len(lst), n)
size = size + 1 if rest else size
for i in range(n):
yield lst[i*size:(i+1)*size]
这里用到的一个窍门是:虽然索引超出列表下标范围时会报错,但切片并不会,只是返回的元素会变少,或干脆返回空列表。下面进行测试
def test(N, n):
lst = list(range(N))
for subset in split_list(lst, n):
print(subset)
In : test(12, 3)
Out:
[0, 1, 2, 3]
[4, 5, 6, 7]
[8, 9, 10, 11]
In : test(12, 5)
Out:
[0, 1, 2]
[3, 4, 5]
[6, 7, 8]
[9, 10, 11]
[]
显然第二个结果不太对劲,虽然的确分成了 n 份,但最后一组里一个元素也没有,这很难称得上是等分。余数不为零的情况下的确会有一些分组“缺斤少两”,但我们还是希望组与组之间最多相差一个元素。为了达成这种均衡(balanced)的分组,下面介绍策略二:前 rest 组含 size + 1 个元素,后 n - rest 组含 size 个元素。如下图所示
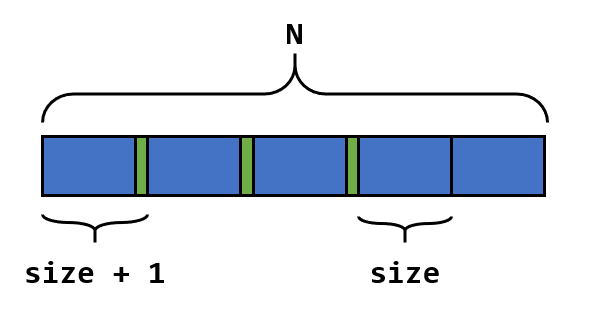
def split_list(lst, n):
size, rest = divmod(len(lst), n)
start = 0
for i in range(n):
step = size + 1 if i < rest else size
stop = start + step
yield lst[start:stop]
start = stop
In : test(12, 3)
Out:
[0, 1, 2, 3]
[4, 5, 6, 7]
[8, 9, 10, 11]
In : test(12, 5)
Out:
[0, 1, 2]
[3, 4, 5]
[6, 7]
[8, 9]
[10, 11]
这次的结果相比策略一更加整齐。当 n > N 时,该函数会用空列表补齐不够的分组。其实还有一个与策略二异曲同工,但仅需一行代码的算法
def split_list(lst, n):
return (lst[i::n] for i in range(n))
理解其原理需要交换除数与被除数的位置:将列表分为 size 份,每份含 n 个元素,另外剩余 rest 个元素归为特殊的一组。第一次循环收集每组的第一个元素,第二次循环收集每组的第二个元素,依次类推,循环 n 次收集到的 n 个列表即为最终结果。rest 个元素会在前 rest 次循环里被收集完,所以后 n - rest 次循环要比前面的循环少一个元素——这与策略二的思路是一致的。测试结果为
In : test(12, 3)
Out:
[0, 3, 6, 9]
[1, 4, 7, 10]
[2, 5, 8, 11]
In : test(12, 5)
Out:
[0, 5, 10]
[1, 6, 11]
[2, 7]
[3, 8]
[4, 9]
每组的长度与策略二相同,但跳步索引使得组内元素并不连续,或许这就是简洁的代价吧。
当然还可以直接调包。more_itertools 包的 divide 函数就可以实现该功能,源码的算法和策略二差不多,区别在于每个分组以迭代器的形式返回。此外这个包里还有按每组元素数进行分组的 chunked 函数,以及可以用缺测值补充长度的 grouper 函数,感兴趣的读者可以去自行查阅。
参考链接
Python split list into n chunks