前言
CALIPSO 卫星的 L2 VFM(Vertical Feature Mask)产品根据激光的后向散射和消光信息,将激光通过的各高度层分类为云或气溶胶。该产品在现实中的表现如下图所示:卫星一边在轨道上移动一边向地面发射激光脉冲,相当于在地面上缓缓拉开一幅“画卷”,VFM 描述了“画卷”上云和气溶胶的分布和分类情况。
处理 VFM 产品的难点在于:
- VFM 数组呈
(N, 5515)的形状,N 表示卫星移动时产生了 N 次观测,但 5515 并非表示有 5515 层高度,而是三种水平和垂直分辨率都不同的数据摊平成了长 5515 的数组。因此处理数据时需要参照文档的说明对 5515 进行变形。 - 文件中的经纬度和时间与 5515 的对应关系。时间数组需要解析成可用的格式。
- 每个 range bin 的分类结果编码到了 16 位的无符号短整型的每个比特上,需要按位解码。
- 网上现成的代码偏少。
网上能找到的代码有:
- CALIOPmatlab:以前 VFM 的在线文档里是给出过 MATLAB 和 IDL 的代码的,但现在链接消失了。这个仓库提供了民间改进后 MATLAB 代码。
- HDF-EOS COMPREHENSIVE EXAMPLES:HDF-EOS 网站的示例,简单易理解。
- MeteoInfo examples: CALIPSO data:基于 MeteoInfo 的代码,还有其它产品的例子。
- Visualization of CALIPSO (VOCAL):CALIPSO 官方基于 Python 2 的可视化工具。
- 星载激光雷达CALIPSO-VFM产品数据读取与显示:MATLAB 代码的讲解。
笔者也曾写过两次教程:
- NCL绘制CALIPSO L2 VFM图像:写得很烂,作图部分可能存在问题。
- Python 绘制 CALIPSO L2 VFM 产品
本文是对旧教程的翻新,会对 VFM 数据的结构进行更多解释,对代码也进行了更新。本文使用 pyhdf 读取 HDF4 文件,用 Matplotlib 3.6.2 画图。为了方便画图,用了一些自制的函数(frykit)。虽然基于 Python,但希望能给使用其它语言的读者提供一点思路。
完整代码已放入仓库 calipso-vfm-visualization。
数据下载
廓线数据的水平和垂直分辨率
CALIPSO 532 nm 波段廓线的水平分辨率为 333 m,名义上垂直分辨率为 15 m。由于廓线原始数据体积过大,地面下载的网络带宽有限,原始数据在卫星上进行了平均处理:15 条连续的廓线构成一个 block,将 block 按高度分为 5 层,每层通过在水平方向和垂直方向上做平均的方式来降低分辨率。结果是对流层下层的廓线数据分辨率较高,高空的廓线数据分辨率较低,在不降低数据可用性的前提下大幅减小了文件体积。具体来说:
- -2.0 ~ -0.5 km:水平分辨率不变,垂直分辨率降为 300 m;block 内含 15 条廓线,高度层内含 5 个 range bin。
- -0.5 ~ 8.5 km:水平分辨率不变,垂直分辨率降为 30 m;block 内含 15 条廓线,高度层内含 290 个 range bin。
- 8.5 ~ 20.1 km:水平分辨率降为 1000 m,垂直分辨率降为 60 m;block 内含 5 条廓线,高度层内含 200 个 range bin。
- 20.1 ~ 30.1 km:水平分辨率降为 1667 m,垂直分辨率降为 180 m;block 内含 3 条廓线,高度层内含 55 个 range bin。
- 30.1 ~ 40.0 km:水平分辨率降为 5000 m,垂直分辨率降为 300 m;block 内含 1 条廓线,高度层内含 33 个 range bin。
在线文档 的图片很好地展示了这一点:
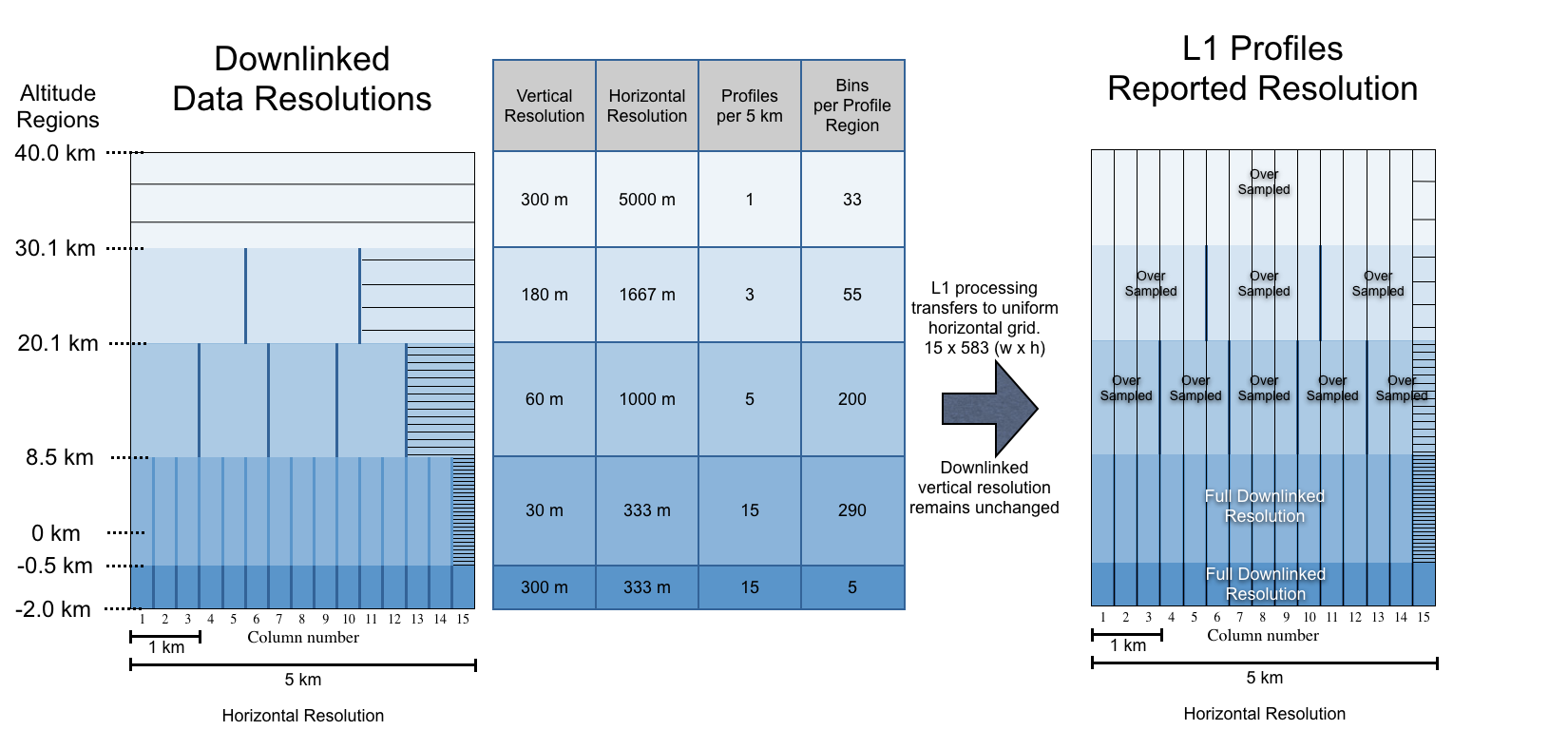
图左是平均处理后 block 里廓线的组成;图中间的表格是各高度层的分辨率参数;图右是说通过水平方向上的重采样就能将五个高度层的廓线数据处理成水平分辨率相同的形式,例如 20.1 ~ 30.1 km 的 3 条廓线每条重复 5 次,就能和底层的 15 条廓线对齐。
VFM 数据的结构
VFM 文件直接用 Panoply 打开,下面列出主要变量:
float Latitude(fakeDim0=4224, fakeDim1=1)float Longitude(fakeDim2=4224, fakeDim3=1)double Profile_UTC_Time(fakeDim4=4224, fakeDim5=1)ushort Feature_Classification_Flags(fakeDim14=4224, fakeDim15=5515)
其中 Feature_Classification_Flags 就是分类结果,4224 表示有 4224 个 block,5515 是将一个 block 的所有 range bin 摊平成一维的结果。如下图所示:
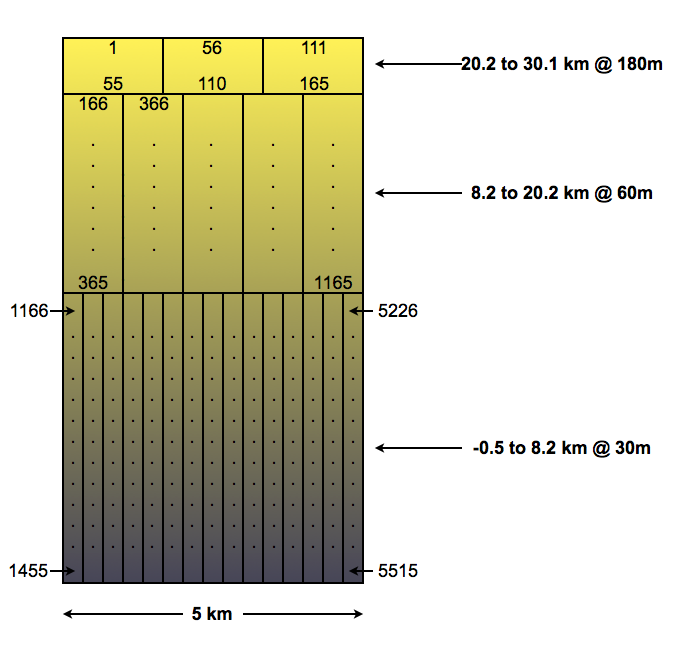
相比上一节的 block 示意图,VFM 的 block 砍掉了 -2.0 ~ -0.5 km 和 30.1 ~ 40.0 km 这两层,只保留了中间三个高度层。因此每个 block 宽 5 km,高 -0.5 ~ 30.1 km。因为 block 里的廓线数据水平和垂直分辨率各不相同,所以无法简单用二维数组表示,只好将其按图中的序号展开成含 5515 个 range bin 的一维数组。例如获取 -0.5 ~ 8.2 km 内的 15 条廓线:
# (N, 15, 290), 廓线高度随下标增大而增大.
fcf1 = fcf[:, 1165:5515].reshape(-1, 15, 290)[:, :, ::-1]
那么如何获取 -0.5 ~ 30.1 km 完整高度的廓线呢?按上节提到的方法对 block 进行水平方向上的重采样,再将 5515 数组变形为 (15, 545) 的二维数组。545 表示共 545 个 range bin,但是存在三种不同的垂直分辨率。然后考虑到 VFM 文件的经纬度只有 N 个点,而非 N * 15 个点,我们对这 15 条廓线做水平平均,得到 N 条与经纬度相匹配的廓线。
具体来说,Longitude、Latitude 和 Profile_UTC_Time 指的是卫星在地面扫过一个 5 km 宽的 block 的时间段里,时间中点对应的经纬度和 UTC 时间。即文件虽然可以 reshape 出 N * 15 条廓线,但只提供了 N 个 block 中点的经纬度坐标和时间戳。因此我们需要将 N * 15 条廓线处理成 N 条廓线,而水平平均便可以做到这一点。考虑到对数值离散的分类结果做平均可能不太合理,笔者的处理是每层只取第一条廓线,然后拼接成完整高度的一条廓线。即取序号为 1 ~ 55、166 ~ 365、1166 ~ 1455,图中“最左边一列”的 3 条廓线拼成一条廓线,再将经纬度和时间戳匹配给它。
VFM 分类的解码
上一节将 Feature_Classification_Flags 处理成了形如 (N, 545) 的二维数组,数据类型为 ushort(即 16 位的无符号短整型)。为了节省存储空间,分类结果被编码到了 ushort 的每个比特上。以表示沙尘气溶胶的数值 46107 为例:

46107 的比特表示是 1011010000011011,从右往左可以分为 7 个字段。例如前 3 个比特 011 代表 Feature Type,即大气类型,此处 011 对应十进制的 3,表示类型为气溶胶;第 10 ~ 12 比特 010 代表 Feature Sub-type,即更细分的类型,此处 010 对应十进制的 2,当 Feature Type 为气溶胶时,2 的 Sub-type 就表示沙尘气溶胶。每个字段的解读方法还请参考 官网表格。
上面的分析采用的是 ushort -> 字符串 -> 子串 -> int 的处理办法,实际编程时采用位运算会更快捷,可以直接在 ndarray 上做向量运算。下面举一个提取 Feature Type 的例子:
'''
等价于
1011010000011011
and 0000000000000111
--------------------
0000000000000011
'''
46107 & 7
& 运算符能让两个整型数在每个比特上取与,再将结果转为十进制。与 7 按位取与,相当于只保留 46107 最右边的 3 个比特,其它位设为零。这个操作可以类比 IP 地址掩码。
如果要提取 Feature Sub-type,最方便的做法是先右移 9 位,再与 7 做按位取与:
'''
右移9位, 左边补零.
1011010000011011 -> 0000000001011010
0000000001011010
and 0000000000000111
--------------------
0000000000000010
'''
# >>优先级高于&.
46107 >> 9 & 7
右移后本来在 10 ~ 12 位的 3 个比特到了最右边,与 7 按位取与得到十进制的结果。
代码实现
VfmReader 类能读取 L2 VFM 文件,以属性的形式提供云气溶胶分类、经纬度、高度和时间戳数组。这里简单认为每条廓线的高度都是相同的,从 -0.5 ~ 20.2 km,垂直分辨率由 30 m、60 m 过渡到 180 m。VOCAL 和 ccplot 的代码里似乎将廓线高度也视为一个二维数组,再通过垂直方向上的线性插值将廓线处理到等距的高度网格上。我看了一下没懂原理,所以这里还是用的简单的高度。
import numpy as np
import pandas as pd
from pyhdf.SD import SD, SDC
class VfmReader:
'''
读取CALIPSO L2 VFM产品的类.
Attributes
----------
lon : (nrec,) ndarray
激光足迹的经度.
lat : (nrec,) ndarray
激光足迹的纬度.
time : (nrec,) DatetimeIndex
激光足迹对应的UTC时间.
height : (545,) ndarray
廓线每个bin对应的高度, 单位为km.
注意存在三种垂直分辨率.
fcf : (nrec, 545, 7) ndarray
解码后的Feature_Classification_Flags.
7对应于文档中7个字段的值.
'''
def __init__(self, filepath):
self.sd = SD(str(filepath), SDC.READ)
def close(self):
'''关闭文件.'''
self.sd.end()
def __enter__(self):
return self
def __exit__(self, *args):
self.close()
@property
def lon(self):
return self.sd.select('Longitude')[:, 0]
@property
def lat(self):
return self.sd.select('Latitude')[:, 0]
@property
def time(self):
# 时间用浮点型的yymmdd.ffffffff表示.
yymmddff = self.sd.select('Profile_UTC_Time')[:, 0]
yymmdd = (yymmddff + 2e7).astype(int).astype(str)
yymmdd = pd.to_datetime(yymmdd, format='%Y%m%d')
ff = pd.to_timedelta(yymmddff % 1, unit='D')
time = yymmdd + ff
return time
@property
def height(self):
height1 = (np.arange(290) + 0.5) * 0.03 - 0.5
height2 = (np.arange(200) + 0.5) * 0.06 + 8.2
height3 = (np.arange(55) + 0.5) * 0.18 + 20.2
height = np.concatenate([height1, height2, height3])
return height
@property
def fcf(self):
# 三个高度层中都只选取第一条廓线来代表5km水平分辨率的FCF.
fcf = self.sd.select('Feature_Classification_Flags')[:]
fcf1 = fcf[:, 1165:1455]
fcf2 = fcf[:, 165:365]
fcf3 = fcf[:, 0:55]
fcf = np.hstack([fcf3, fcf2, fcf1])[:, ::-1]
# 利用位运算进行解码.
shifts = [0, 3, 5, 7, 9, 12, 13]
bits = [7, 3, 3, 3, 7, 1, 7]
fcf = fcf[:, :, None] >> shifts & bits
return fcf
画图例子
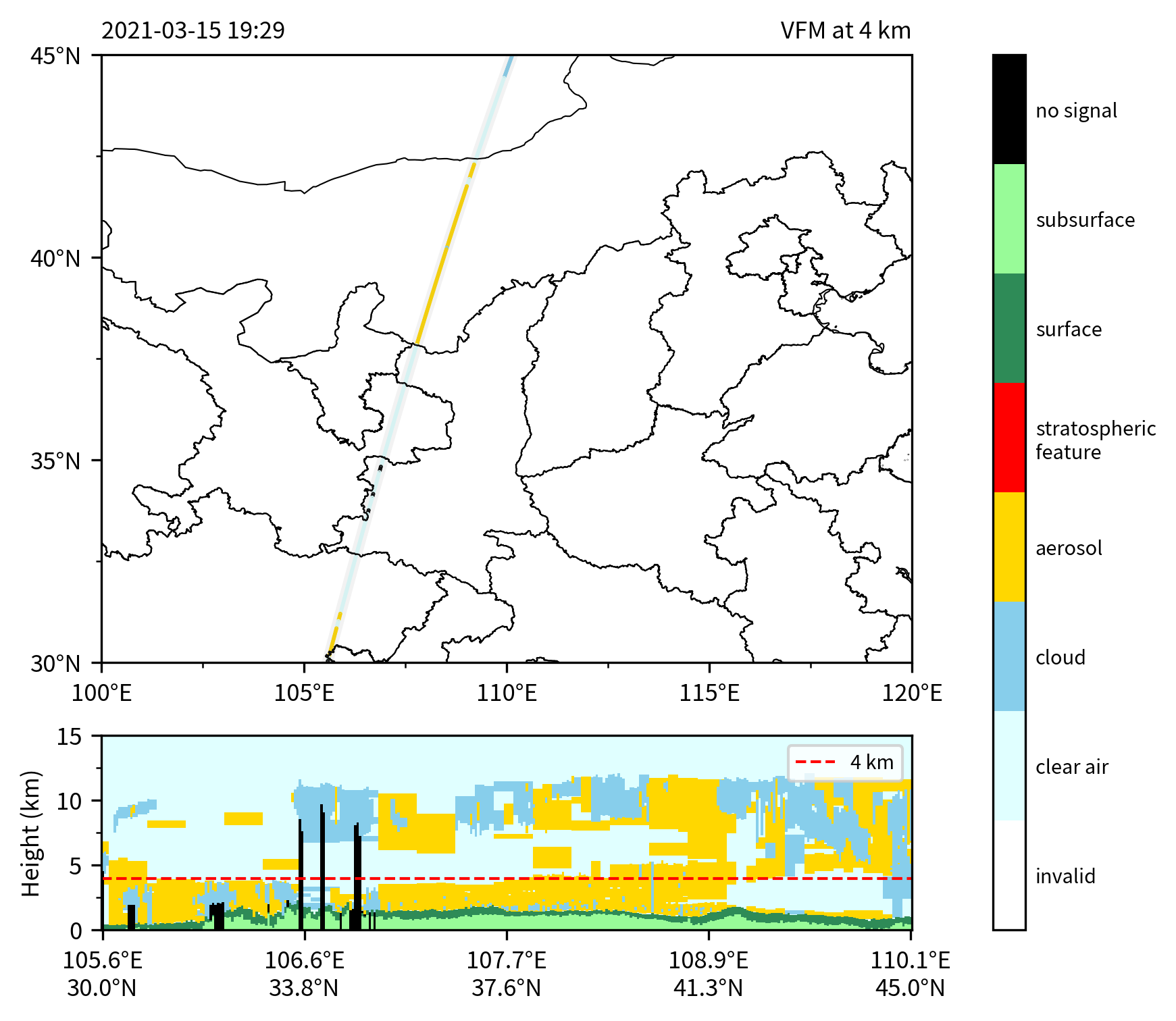
以 2021 年 3 月 15 日中国北方的沙尘暴天气为例,画出 Feature Type:
from pathlib import Path
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
plt.rcParams['font.family'] = 'Source Han Sans SC'
import cartopy.crs as ccrs
from vfm_reader import VfmReader
from frykit.calc import region_ind
import frykit.plot as fplt
# 读取文件.
dirpath = Path('../data')
filepath = dirpath / 'CAL_LID_L2_VFM-Standard-V4-21.2021-03-15T19-18-09ZN.hdf'
with VfmReader(filepath) as reader:
lon = reader.lon
lat = reader.lat
time = reader.time
height = reader.height
fcf = reader.fcf
# 用地图显示范围截取数据.
extents = [100, 120, 30, 45]
scan_mask = region_ind(lon, lat, extents)
lon = lon[scan_mask]
lat = lat[scan_mask]
time = time[scan_mask]
fcf = fcf[scan_mask]
ftype = fcf[:, :, 0]
# 构造cmap和norm.
colors = [
'white', 'lightcyan', 'skyblue', 'gold',
'red', 'seagreen', 'palegreen', 'black'
]
ticklabels = [
'invalid', 'clear air', 'cloud', 'aerosol',
'stratospheric\nfeature', 'surface', 'subsurface', 'no signal'
]
cmap, norm, ticks = fplt.get_qualitative_palette(colors)
# 构造截面图所需的x轴刻度.
x, xticks, xticklabels = fplt.get_cross_section_xticks(lon, lat, ntick=5)
crs = ccrs.PlateCarree()
fig = plt.figure(figsize=(8, 6))
# 绘制地图.
ax1 = fig.add_axes([0.1, 0.4, 0.8, 0.5], projection=crs)
fplt.add_cn_province(ax1, lw=0.5)
ax1.coastlines(resolution='10m', lw=0.5)
fplt.set_map_ticks(ax1, extents, dx=5, dy=5, mx=1, my=1)
ax1.tick_params(labelsize='small')
# 画出VFM在h0高度的水平分布.
h0 = 4
ind = np.nonzero(height <= h0)[0][-1]
ax1.plot(lon, lat, lw=4, c='gray', alpha=0.1, transform=crs)
ax1.scatter(
lon, lat, c=ftype[:, ind], s=0.2,
cmap=cmap, norm=norm, transform=crs
)
mean_time = time.mean().strftime('%Y-%m-%d %H:%M')
ax1.set_title(mean_time, loc='left', fontsize='small')
ax1.set_title(f'VFM at {h0} km', loc='right', fontsize='small')
# 画出VFM的垂直剖面.
ax2 = fplt.add_side_axes(ax1, loc='bottom', pad=0.06, width=0.16)
pc = ax2.pcolormesh(x, height, ftype.T, cmap=cmap, norm=norm, shading='nearest')
ax2.axhline(h0, ls='--', c='r', lw=1, label=f'{h0} km')
ax2.legend(loc='upper right', fontsize='x-small')
# 设置ax2的坐标轴.
ax2.set_xticks(xticks)
ax2.set_xticklabels(xticklabels)
if filepath.stem[-1] == 'N':
ax2.invert_xaxis()
ax2.set_ylim(0, 15)
ax2.set_ylabel('Height (km)', fontsize='small')
ax2.yaxis.set_major_locator(mticker.MultipleLocator(5))
ax2.yaxis.set_minor_locator(mticker.AutoMinorLocator(2))
ax2.tick_params(labelsize='small')
# 设置colorbar.
cax = fplt.add_side_axes([ax1, ax2], loc='right', pad=0.05, width=0.02)
cbar = fig.colorbar(pc, cax=cax)
cbar.set_ticks(ticks)
cbar.set_ticklabels(ticklabels)
cbar.ax.tick_params(length=0, labelsize='x-small')
plt.show()
如果要画气溶胶的 Sub-type,只需要在上面的代码中进行少量修改:
ftype = np.where(fcf[:, :, 0] == 3, fcf[:, :, 4], 0)
colors = [
'white', 'blue', 'gold', 'red',
'green', 'brown', 'black', 'gray'
]
ticklabels = [
'not aerosol', 'clean\nmarine', 'dust', 'polluted\ncontinental',
'clean\ncontinental', 'pullted\ndust', 'smoke', 'other'
]
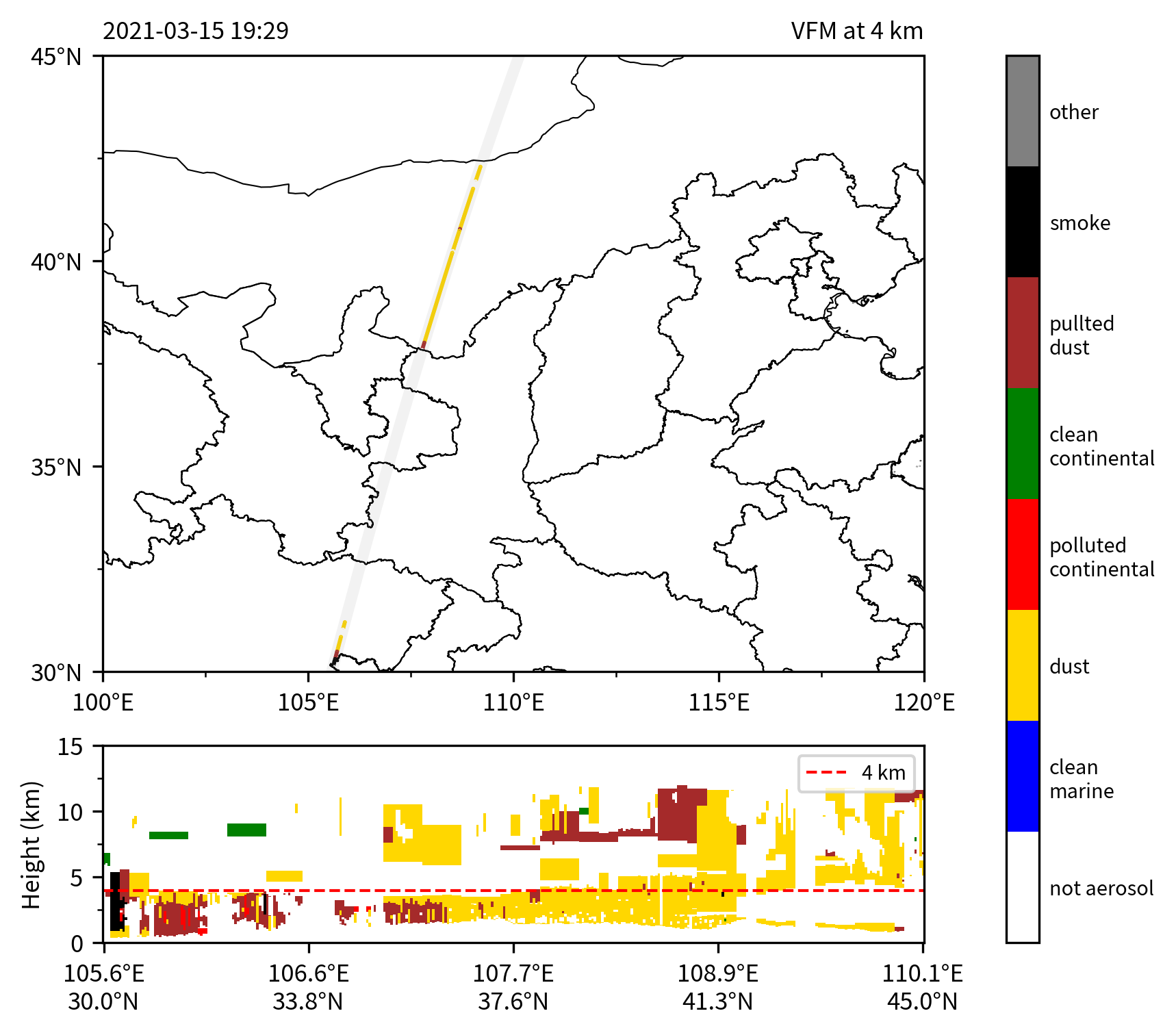
注意图中 'not aerosol' 的像元,实际上包含 Feature Type 不为气溶胶和 Sub-type 无法确定的两类像元。
结语
很好,位运算学得很开心。