现实中观测的数据或多或少会有缺失的部分,通常称为缺测值(missing value)。NumPy 因为设计上的问题,不能像 R 和 NCL 那样原生支持缺测类型,而是有两种处理缺测的实现:NaN 和 masked array。下面便来依次介绍它们。代码基于 NumPy 1.20.1。
NaN
NaN(not a number)由 IEEE 754 浮点数标准首次引入,是一种特殊的浮点数,用于表示未定义或不可表示的值(即缺测)。NaN 的位模式(bitpattern)是符号位任意,阶码全为 1,尾数最高位表示 NaN 类型,尾数剩余的位不全为 0。作为对比,无穷大的位模式是,符号位决定无穷的正负,阶码全为 1,尾数全为 0。
NumPy 中用 np.nan 表示一个 NaN,我们可以把数组中的元素赋值为 np.nan,以表示该元素缺测。NaN 的特性如下
- NaN 是一种特殊的浮点数,它可以是 float32 或 float64,但是通常没有其它类型的 NaN。所以不要尝试给整数类型的数组元素赋值为 NaN,不然会发生类型错误。
- 当 NaN 进行加减乘除时,结果也会变为 NaN。当 NaN 参与比较大小时,结果总是 False。
- 由于 NaN 的位模式的任意性,一般来说
np.nan == np.nan的结果为 False。要判断数组中是否含有 NaN 的话,有专门的函数np.isnan来进行判断。 - 当把数组中的元素赋值为 NaN 时,会直接覆盖掉该元素原有的值。
一般我们得到的原始数据中的缺测值不会直接用 NaN 表示,而是会用人为给定的填充值(fill value)表示,例如用 -9999 指示某个数据缺测。在读取为 ndarray 后,为了避免这些 -9999 参与计算,需要把它们赋值为 NaN,此时可以用 np.isclose 函数来筛选出填充值
fill_value = -9999.0
mask = np.isclose(data, fill_value)
data[mask] = np.nan
有时我们需要利用数据中剩下的有效数据进行计算,那么便需要忽略(ignore)这些缺测值。实现方法有两种,一是利用np.isnan函数筛选出有效值再进行计算
data_valid = data[~np.isnan(data)]
mean_value = np.mean(data_valid)
二是使用一些会自动跳过 NaN 的特殊函数
mean_value = np.nanmean(data)
std_value = np.nanstd(data)

如上图所示,这样的函数以 “nan” 作为前缀,可惜这种函数不过十来个。并且当数组元素(沿某一维度)全为 NaN 时,这些函数的行为还会有所不同
nanargmin和nanargmax会直接报错。nansum、nancumsum、nanprod和nancumprod会将 NaN 替换为 0 或 1,再计算出有意义的结果。- 其它函数会报警(空切片、全 NaN、自由度小于 0),并返回 NaN。
所以需要小心全为 NaN 的情况。
NumPy 的普通函数接受含 NaN 的数组时,效果五花八门:有的会报错,有的会返回 NaN,有的会返回正确的结果,有的会返回错误的结果。此外,有些 SciPy 的函数能够通过 nan_policy 参数指定如何对待 NaN。总之,使用 NaN 时要多加小心。
Masked Array
NumPy 中对缺测值还有另一种实现——masked array。思路是创建一个和 data 数组同样形状的布尔类型 mask 数组,两个数组的元素一一对应。若 mask 数组中某个位置的元素值为 True,那么 data 数组中对应的元素则被判定为 masked(即缺测);若值为 False,则 data 数组对应的元素判定为有效。
Data 数组和 mask 数组打包而成的对象就称作 masked array,属于 ndarray 的子类,继承了许多 ndarray 的方法。NumPy 中的 ma 模块提供了创建和操作 masked array 的功能。
masked array 的特性如下
- 对整型、浮点型、布尔型数组都适用,因为 mask 数组并不依赖于 NaN 的位模式。
- 缺测的元素进行加减乘除和比较大小时,结果也会变成缺测。
- 不保证缺测元素的原始值在经过复杂计算后依然保留。
- 能够记录给定的填充值。
ma模块提供大量能够忽略缺测值的计算函数,masked array 对象也带有许多方法。
下面介绍使用 masked array 的基本方法
import numpy.ma as ma
# 直接给出原始数组和mask来创建masked array
x = ma.array([1, 2, 3], mask=[True, False, False])
# 返回原始数组
x.data
# 返回mask数组
x.mask
# 指定填充值
x.fill_value = -9999
# 把data中数值等于fill_value的元素设为masked状态,并指定填充值为fill_value
x = ma.masked_equal(data, fill_value)
# 同上,但是内部使用了np.isclose方法,更适用于浮点数
x = ma.masked_values(data, fill_value)
# 把data中数值大于/小于(等于)fill_value的元素设为masked状态
# 填充值会被设定为默认值
x = ma.masked_greater(data, value)
x = ma.masked_greater_equal(data, value)
x = ma.masked_less(data, value)
x = ma.masked_less_equal(data, value)
# 用条件式决定是否masked
# 填充值会被设定为默认值
x = ma.masked_where(data > 0, data)
# 把NaN和inf的元素mask掉
x = ma.masked_invalid(data)
# 统计有效值的个数
n = x.count()
# 使用忽略缺测值的函数和方法
mean_value = ma.mean(x)
mean_value = x.mean()
cos_value = ma.cos(x)
# 从masked array中提取出有效值,返回一维的ndarray
x_valid = x[~x.mask]
x_valid = x.compressed()
# 设定fill_value
x.fill_value = 0
# 填充缺测值,返回ndarray,默认使用fill_value属性填充
y = x.filled()
Masked array 比较大小后得到的布尔数组依旧是 masked array,并且可能含有缺测部分,如果再用这个布尔数组去索引 masked array,那么结果里也会含有缺测部分,此时只要再使用 compressed 方法,就能得到真正不含缺测的有效值。例如
# x: [1, 2, -]
x = ma.array([1, 2, 3], mask=[False, False, True])
# cond: [False, True, -]
cond = x >= 2
# x_valid: [2, -]
x_valid = x[cond]
# x_valid_true: [2]
x_valid_true = x.compressed()
下面再来讲讲如何修改 mask。首先可以直接修改 mask 数组的数值。又或者,可以用模块中的 ma.masked 来进行修改,这是一个可以设置元素缺测状态的常量
# 把第一个元素设为 masked
x[0] = ma.masked
# 全部设为缺测
x[:] = ma.masked
需要注意,模块中还存在一个 ma.nomask 量,但它本质上是布尔类型的 False,所以不要用它来做上面的操作,否则会导致元素的数值直接变为 0。
除此之外,还有一种方法是直接给处于 masked 状态的元素赋值,这样会让元素不再缺测,但如果 masked array 的 hard_mask 参数为 True 的话(默认为 False),会拒绝这样的直接改写。个人觉得最好不要这样直接改写,所以对此有需求的读者可以参考 NumPy 文档的说明。
类似于 NaN 一节的讨论,若 masked array(沿某一维度)全部缺测时,用于 masked array 的函数和方法均能直接返回缺测,而不会弹出乱七八糟的报错和警告,这一点比较符合直觉。可以看出 masked array 对于全部缺测的情况更为宽容一些。
如果使用 NumPy 的普通函数来操作 masked array 的话,经常无法正确处理缺测值,并且会返回 ndarray 对象。所以 ma 模块提供了很多同名的但适用于 masked array 的函数,例如 concatenate、hstack、vstack、where 等。此外 SciPy 中还存在一个 stats.mstats 模块,专门提供处理 masked array 的统计函数。
两种方法的对比
首先指出 masked array 相比 NaN 方法的优势
- 把数据、缺测值位置,和填充值打包到了一起,当数组特别多时,更加易于管理。
- 对于整型数组和布尔数组也能使用。
- 用于处理 masked array 的函数远多于处理 NaN 的函数。
- 对于全部缺测的情况更为宽容。
但是 masked array 的缺点也是显而易见的
- 多附带了一个布尔数组,增加了内存的消耗。
- 计算上可能会更慢。
下面就举一个测试计算速度的例子
import numpy as np
import numpy.ma as ma
x = np.random.rand(1000, 1000)
flag = np.random.randint(0, 2, (1000, 1000))
# 设置NaN数组
x_nan = x.copy()
x_nan[flag] = np.nan
# 设置masked array
x_mask = ma.array(x, mask=flag)
接着用 IPython 的命令进行测试
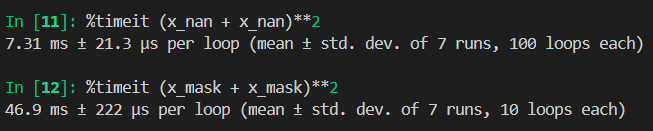
可以看到计算速度慢上 6 倍之多。不过有一说一,我在使用过程也碰到过 masked array 反而更快的情况。所以到底选择哪一种实现,还得由具体场景、测试结果,以及自己的使用习惯来决定。
还有别的处理方式吗?
Pandas 和 xarray 都采用了 NaN 的实现方式,其对象的许多方法都默认开启跳过 NaN 的 skipna 的选项。其中 pandas 从 1.0 版本开始,实验性地增加了类似于 masked array 的实现——pd.NA,使浮点型以外的数据类型也能用上缺测值,有兴趣的读者可以去试试。
Matplotlib 中的缺测值
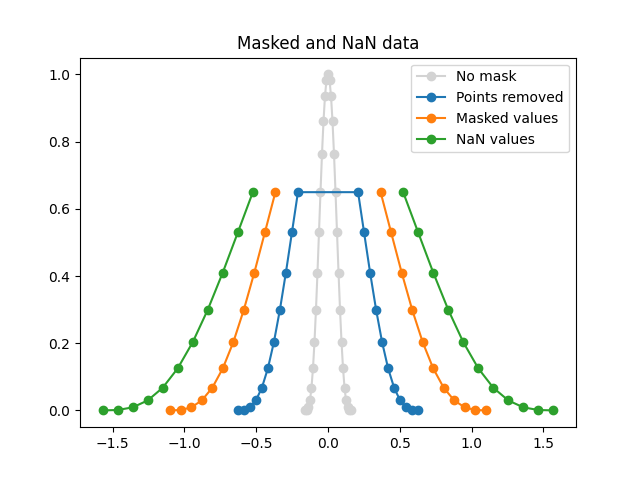
如果是使用简单的 plt.plot 函数,NaN 或者 masked value 的点会被认为数据在那里断开了,效果如下图
不过 plt.bar 会产生警告,并把 masked value 转换为 nan。
对于 plt.imshow、plt.pcolor,和 plt.pcolormesh,它们绘制的是色块,NaN 或者 masked value 所在的色块默认为透明的。如果要用颜色指示出缺测值,需要调整 colormap 的设置
import copy
# 使用copy以免影响全局的colormap
cmap = copy.copy(plt.cm.viridis)
# 设置缺测值的颜色和透明度
cmap.set_bad('gray', 1.0)
下面的例子中,缺测值的颜色被设定成蓝色
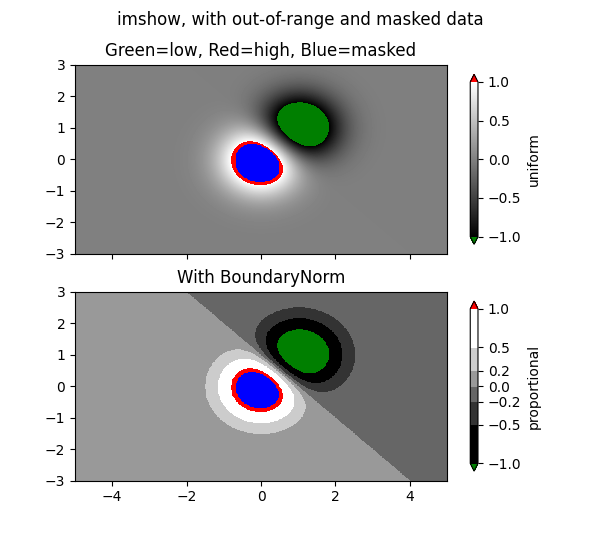
以上两个例子都来自 Matplotlib 官网,代码见文末的参考链接。
而对于填色图 plt.contourf,缺测值区域不会被画出,会直接露出 axes 的背景色,所以可以通过修改背景色来表示缺测的颜色。聊胜于无的是,还可以通过 corner_mask 参数指定缺测区域的边角画法。不过一般还是建议经过插值等填补处理后再来画填色图吧。
参考链接
NumPy 的文档和一些文章
NEP 12 — Missing Data Functionality in NumPy
NEP 26 — Summary of Missing Data NEPs and discussion
pandas 的文档
Wiki 和 stack overflow 上的讨论
Why are Numpy masked arrays useful?
Matplotlib 的缺测