需求
以前处理功率时间序列时经常遇到一大段时间里功率值虽然没有缺失,但全是零的异常情况,为了找出这些连续为零的时段,当时设计了一个统计序列里零值连续出现次数的函数,效果如下图所示:
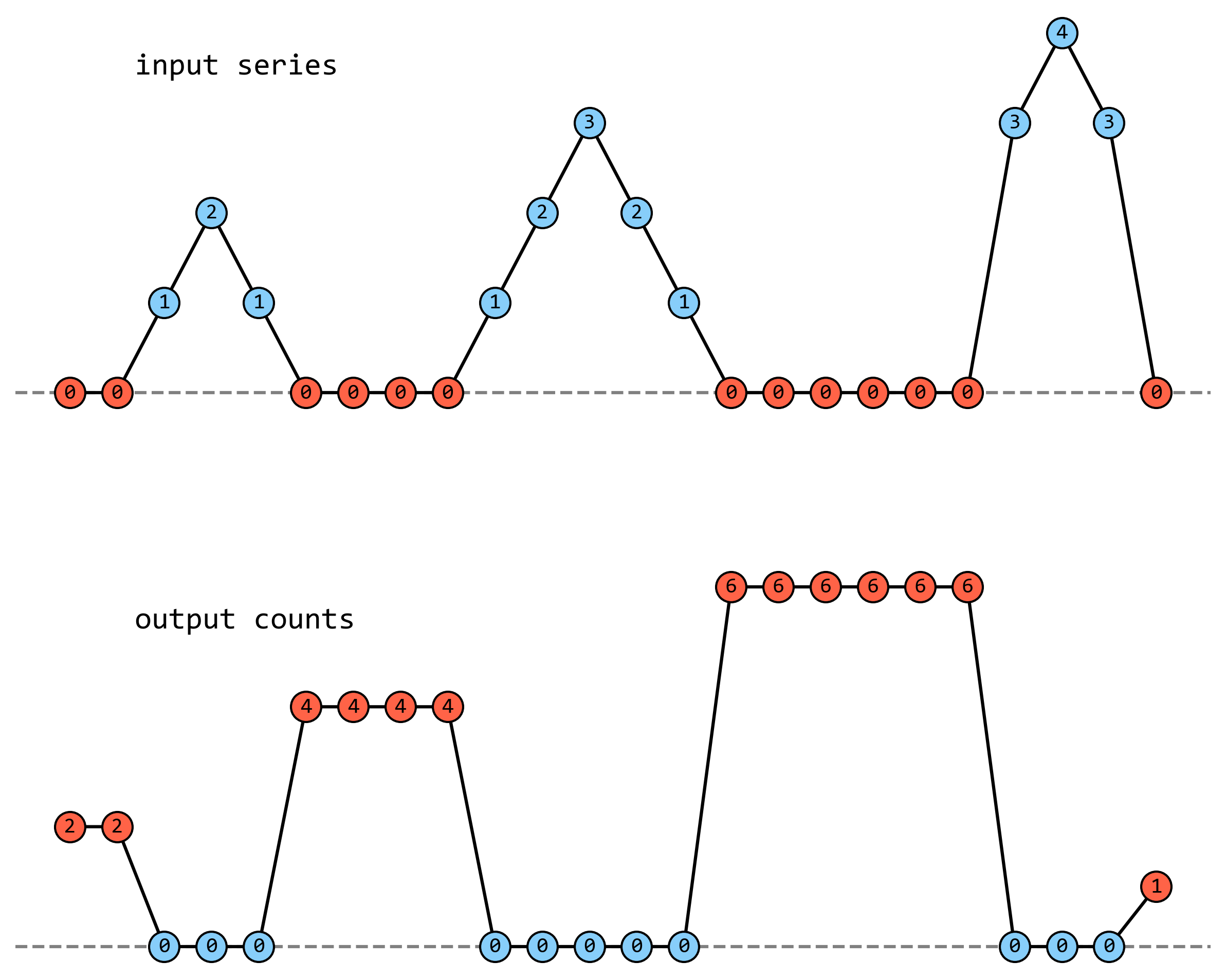
输入序列是
series = np.array([0, 0, 1, 2, 1, 0, 0, 0, 0, 1, 2, 3, 2, 1, 0, 0, 0, 0, 0, 0, 3, 4, 3, 0])
其中有四段零值,长度依次为 2、4、6、1。输出序列与输入序列等长,输入序列中非零位置的数值为零,零值位置数值为零值连续出现的次数。
这个结果乍看之下不知道怎么使用,这里举个简单的例子:假设该时间序列步长为 1 小时,认为连续出现一天的零值就说明这段数据有问题,在做进一步数据分析前应该剔除。而利用上述的函数就能快速去除问题段落:
counts = count_consecutive_zeros(series)
series = series[counts < 24]
最近又频繁用到这个函数,但回看源码时却发现看不懂原理了,不禁恼羞成怒,遂用本文留作复习的笔记。
算法
def count_consecutive_zeros(series):
mask = series == 0
value_id = np.r_[0, np.diff(mask).cumsum()]
_, unique_counts = np.unique(value_id, return_counts=True)
value_counts = unique_counts[value_id]
value_counts[~mask] = 0
return value_counts
接下来逐行讲解:
mask = series == 0
首先用布尔数组 mask 标出哪些元素是 0,哪些不是。严格来说浮点数和 0 做比较应该用 np.isclose,这里为了简单直接用的 ==。
value_id = np.r_[0, np.diff(mask).cumsum()]
然后对 mask 做差分,注意布尔数组差分的结果依旧是布尔类型。发现 series 里相邻两个元素如果出现了零 -> 非零或非零 -> 零的跳变时,对应 mask 的差分值会是 True。接着对差分求累计和,发生跳变的每个段落会按跳变次数得到对应的数值,由于这个数值是唯一的,相当于每个段落都获得了唯一的 ID。
注意对形为 (n + 1,) 的数组应用 np.diff,会得到形如 (n,) 的数组,并且第一个段落的 ID 为 0,所以用 np.r_ 在累计和前补一个零。
_, unique_counts = np.unique(value_id, return_counts=True)
value_counts = unique_counts[value_id]
value_counts[~mask] = 0
np.unique 函数返回唯一且有序的段落 ID,用 return_counts 参数返回每个 ID 出现的次数,即每个段落的长度。考虑到段落 ID 从零开始逐一递增,所以 unique_counts[i] 就代表第 i 个段落的长度。那么用 value_id 对 unique_counts 做花式索引,即可将段落长度填到段落位置上,让结果与 series 形状相同。最后我们只关心零值段落的计数,所以用 ~mask 将非零段落的计数置零。
这里原先写的是
value_counts = unique_counts[np.searchsorted(unique, value_id)],经评论区 ff-script 指正,修改成了直接索引。
简单来说,这步是按 ID 对段落进行分组,统计段落长度,再变换回原来的序列里。熟悉 Pandas 的读者应该会想到用 groupby 和 transform 秒了:
value_id = pd.Series(value_id)
value_count = value_id.groupby(value_id).transform('count')
value_count[~mask] = 0
这里为了不引入 Pandas 的依赖,仅用 NumPy 实现。
这坨描述可能还是比较抽象,再给出每步计算的中间结果:
[0, 0, 1, 2, 1, 0, 0, 0, 0, 1, 2, 3, 2, 1, 0, 0, 0, 0, 0, 0, 3, 4, 3, 0] # series
[T, T, F, F, F, T, T, T, T, F, F, F, F, F, T, T, T, T, T, T, F, F, F, T] # mask
[F, T, F, F, T, F, F, F, T, F, F, F, F, T, F, F, F, F, F, T, F, F, T] # np.diff(mask)
[0, 0, 1, 1, 1, 2, 2, 2, 2, 3, 3, 3, 3, 3, 4, 4, 4, 4, 4, 4, 5, 5, 5, 6] # value_id
[2, 2, 0, 0, 0, 4, 4, 4, 4, 0, 0, 0, 0, 0, 6, 6, 6, 6, 6, 6, 0, 0, 0, 1] # value_counts
时间复杂度是 np.unique 排序的 O(nlog(n)) 加上花式索引的 O(n),大概是 O(nlog(n))。
代码
最后封装的代码是
from collections.abc import Callable
from typing import Union
import numpy as np
from numpy.typing import ArrayLike, NDArray
def count_consecutive_trues(mask: ArrayLike) -> NDArray:
'''统计布尔序列里真值连续出现的次数,返回长度相同的序列。'''
mask = np.asarray(mask, dtype=bool)
assert mask.ndim == 1
if len(mask) == 0:
return np.array([], dtype=int)
value_id = np.r_[0, np.diff(mask).cumsum()]
_, unique_counts = np.unique(value_id, return_counts=True)
value_counts = unique_counts[value_id]
value_counts[~mask] = 0
return value_counts
函数的输入是布尔序列,想要统计零值就传入 series == 0,想要统计缺测就传入 np.isnan(series)。另外还加上了类型和防御性语句。
应用
只线性插值填补缺测长度小于等于 3 的缺口:
s = pd.Series([1, np.nan, 2, 3, np.nan, np.nan, 4, np.nan, np.nan, np.nan, np.nan, 5])
counts = count_consecutive_trues(s.isna())
s.interpolate().mask(counts > 3)
从降水序列中区分出下雨时段,要求下雨时段之间至少有三个时次没有下雨:
rain = np.array([0, 1, 2, 1, 0, 0, 0, 0, 1, 2, 3, 4, 3, 0, 1, 0, 0])
def trim_zeros(arr):
'''去掉首尾的零值'''
i, j = np.nonzero(arr > 0)[0][[0, -1]]
return arr[i:j+1].copy()
def split_consecutive_trues(mask):
'''分段返回布尔数组里连续真值段落的索引'''
inds = np.nonzero(mask)[0]
return np.split(inds, np.nonzero(np.diff(inds) != 1)[0] + 1)
rain = trim_zeros(rain)
counts = count_consecutive_trues(rain == 0)
rain_events = [rain[inds] for inds in split_consecutive_trues(counts < 3)]